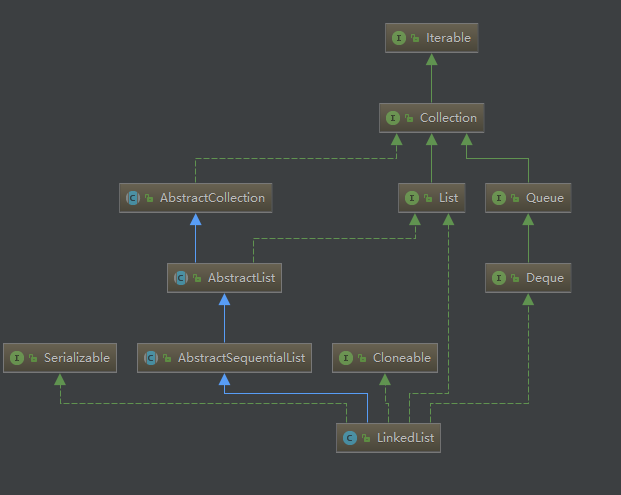
publicbooleanadd(E e){ linkLast(e); returntrue; } /** * Links e as last element. */ voidlinkLast(E e){ final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else l.next = newNode; size++; modCount++; }
if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } }
LinkedList使用二分查找来看 index 离 size 中间距离来判断是从头结点正序查还是从尾节点倒序查。这样的效率是非常低的,特别是当 index 距离 size 的中间位置越远时。
voidlinkLast(E e){ final Node<E> l = last; //创建一个节点,将 prev 指针指向链表的尾节点 final Node<E> newNode = new Node<>(l, e, null); last = newNode; //将last指针指向新创建的这个节点 if (l == null) //如果当前链表为空,那么将头指针也指向这个节点 first = newNode; else //将链表的尾节点的next指针指向新建的节点,这样就完整的实现了在链表尾部添加一个元素的功能 l.next = newNode; size++; modCount++; }
//出队功能,从尾出队 //在队列头部取出一个元素并删除, 队列操作建议使用这个方法 public E poll(){ final Node<E> f = first; return (f == null) ? null : unlinkFirst(f); }
//同上,都调用了 unlinkFirst 方法 public E pollFirst(){ final Node<E> f = first; return (f == null) ? null : unlinkFirst(f); }
private E unlinkFirst(Node<E> f){ // assert f == first && f != null; final E element = f.item; final Node<E> next = f.next; f.item = null; f.next = null; // help GC first = next; if (next == null) last = null; else next.prev = null; size--; modCount++; return element; }
// addFirst 调用的就是 linkFirst ,这段代码就是实现将元素添加的链表头部。 privatevoidlinkFirst(E e){ final Node<E> f = first; // 创建一个新元素,将元素的 next 指针指向当前的头结点 final Node<E> newNode = new Node<>(null, e, f); // 将头指针指向这个节点。 first = newNode; if (f == null) // 如果当前节点为空,则把尾指针指向这个节点。 last = newNode; else // 将当前头结点的 prev 指针指向此结点。 f.prev = newNode; size++; modCount++; }
// 弹出顶部结点。 public E pop(){ return removeFirst(); }
// removeFirst 调用的就是 unlinkFirst,unlinkFirst 实现将链表顶部元素删除 private E unlinkFirst(Node<E> f){ // assert f == first && f != null; final E element = f.item; final Node<E> next = f.next; f.item = null; f.next = null; // help GC first = next; if (next == null) last = null; else next.prev = null; size--; modCount++; return element; }
// 获取顶部结点,但是不删除 public E peek(){ final Node<E> f = first; return (f == null) ? null : f.item; }